

spark-runtime-architecture-24tutorials
How Spark Jobs are Executed-
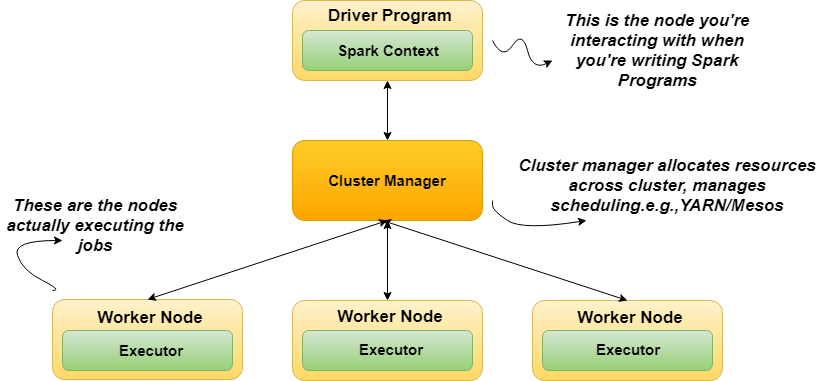
A Spark application is a set of processes running on a cluster.
All these processes are coordinated by the driver program.
The driver is:
-the process where the main() method of your program run.
-the process running the code that creates a SparkContext, creates RDDs, and stages up or sends off transformations and actions.
These processes that run computations and store data for your application are executors.
Executors:
-Run the tasks that represent the application.
-Return computed results to the driver.
-Provide in-memory storage for cached RDDs.
Execution of a Spark program:
1. The driver program runs the Spark application, which creates a SparkContext upon start-up.
2. The SparkContext connects to a cluster manager (e.g., Mesos/YARN) which allocates resources.
3. Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application.
4. Next, driver program sends your application code to the executors.
5. Finally, SparkContext sends tasks for the executors to run.